* Use travis_retry in travis builds to retry the farm tests
* travis_retry is a bash function, so it can be called only from current bash
* Update .travis.yml
* Update .travis.yml
We're planning on using the branch apache-parser-v2 allowing us to incrementally work on the new Apache parser and feel comfortable landing temporary test code that we don't really want in master.
The apache-parser-v2 branch is created and locked down, but neither Travis or AppVeyor are configured to run tests on it. See #7230. This PR fixes that problem.
This could probably just land in the apache-parser-v2 branch, but why unnecessarily deviate the branch from master? It doesn't hurt anything there. Once it lands, I'll get this added to the apache-parser-v2 branch too.
* Run tests on apache-parser-v2.
* add comment
* Don't run full test suite on apache-parser-v2.
* Update virtualenv to the latest version.
* Use venv from pip and pin more packages.
* Pin codecov.
* update appveyor config
* Write the path separator backwards.
* s/pip_install.py install/pip_install.py
* Prefix tools\\pip_install.py with python exe.
* Upgrade py to fix AppVeyor failures.
* add back comment
* Update virtualenv with CERTBOT_NO_PIN.
* Pass -U to upgrade tox and deps.
* Upgrade virtualenv.
https://github.com/certbot/certbot/pull/7190/files removed our only le_auto_* tests on PRs. This PR fixes that by running le_auto_xenial on every PR which also includes running modification-check.py like we used to for Trusty.
With the various optimizations already done and upcoming (certbot-ci), the time execution of integration tests have significantly decreased, allowing potentially a complete execution of a Travis PR job to be done within 5min30s.
However, one job is significantly longer that the other ones after this migration: this is nginx_compat, that takes more that 11min to finish. I tried to split the nginx_compat in terms of tested configuration and of tests to execute (auth, install, enhance). Both are not satisfactory:
splitting by configuration may work, but add a significant complexity in the tests
splitting by tests type is supported almost out-of-the-box, but fails to make two fast tests (see https://travis-ci.org/adferrand/certbot/builds/525892885?utm_source=github_status&utm_medium=notification for instance)
Since these tests are designed to check corner cases on the nginx parser, this is mostly useless to execute them on each PR, as the nginx parser is rarely updated.
After some discussion with @bmw, I think that we can just move the nginx_compat from the PR tests to the nightly tests. This PR does that.
You can see the full test suite running at https://travis-ci.com/certbot/certbot/builds/112291892.
A few noteworthy things:
--fast is included because without, the tests would sometimes reach Travis' 50 minute timeout even with 1 test script per Travis build.
The only script that is run at release time which is not being run here is https://github.com/certbot/certbot/blob/master/tests/letstest/scripts/test_tests.sh because that script runs tests on the packages installed by certbot-auto which won't be updated until midway through a release.
We check TRAVIS_PULL_REQUEST and error out if it is not false for simplicity which should be fine because these tests are never run on PRs. The reason it's more complex to run test farm tests on PRs is the test farm tests need a named branch to pull from and Travis effectively merges the PR into the target branch before running tests complicating this.
I don't think this should block this PRs, but the one final change we may want to make to the current setup is #7071.
* Add encrypted private key.
* Add test farm tests to tox and travis.
* Change magic profile name.
* Further split test farm tests.
* Build local branch.
* more depth
* Connect certbot-ci to travis. Remove old bash files.
* Configure test-everything
* Protect against import error
* Remove unused ignore
* Better handling of urllib3
* Correct path
* Remove a warning
* Correct call
* Protect atexit register execution
* Update docs/contributing.rst
Co-Authored-By: Brad Warren <bmw@users.noreply.github.com>
* Update docs/contributing.rst
Co-Authored-By: Brad Warren <bmw@users.noreply.github.com>
* Add again some bash scripts to avoid breaking to much retro-compatiblity on third party scripts
* Move boulder-v1 and boulder-v2 in nightly tests
* Separate oldest unit tests and oldest integration tests
* Remove try/except
* Test integration included in toxenv
* Add a wait to avoid a transient issue on OCSP status in oldest tests
* Clean travis.yml, split other tests
* Remove useless config
* Update .travis.yml
Co-Authored-By: Brad Warren <bmw@users.noreply.github.com>
* Update tox.ini
* Update tox.ini
* Remove pytest-sugar
* Remove empty pytest.ini, tests are working without it
In #7019, a solution has been integrated to fix oldest tests execution in the corner cases described in #7014.
However this solution was not very satisfactory, as it consists in making a --force-reinstall for all requirements on each oldest tests (apache, certbot, acme, each dns plugin ...). As a consequence, the overall execution time of these tests increased from 5 min to 10 min.
In this PR I propose a more elegant solution: instead of reinstalling all dependencies, we force reinstall only the requirements themselves describe in the relevant oldest-requirements.txt files. This way only the packages that are potentially ignored by pip because they exists locally (acme, certbot, ...) are reinstalled.
The result is the same than in #7019 (we are sure that all packages are really installed by pip), but the very limited number of force reinstalled package here make the impact on execution time negligible.
As a consequence, I revert back also the tox environments to execute all oldest tests together.
A successful execution of oldest tests using this PR material in the context of a point release can be seen here: https://travis-ci.org/adferrand/certbot/builds/527513101
Fixes#7014.
Using a --force-reinstall (only for oldest tests), dependencies are properly reinstalled. Since this action significantly increases the execution time of oldest tests, I split them into two parts to allow their parallel execution by Travis.
We will need to find a better way to solve this in the future.
An example of successful execution of oldest tests in the situation of a point release can be found here: https://travis-ci.org/adferrand/certbot/builds/527475532
* Fix for oldest requirements
* Split oldest tests
* Update a comment
So, we observed lately several inconsistencies in how Codecov behave toward the CI pipeline for PRs in Certbot. One example is #6888. The most annoying thing is that the build of PR is **temporary** marked as failed, until all coverage are run.
The correction on the latter is done in two PRs. This is the first part.
TL;DR
This PR separates the Codecov report in two: one for coverage executed on Windows, one for Linux. This is the correct way to do regarding our current CI pipeline. Actions are required by a GitHub administrator of Certbot once this PR is merged.
Complete explanation
So the failure stated in the introduction is essentially due to several things interacting together:
* AppVeyor generates a coverage report for Windows, that have a coverage value a little lower than on Linux (96%)
* Travis generates a coverage report for Linux. Its coverage is higher, and slowly decrease as more specific Windows code is added to Certbot, that cannot be tested on Travis
* Since AppVeyor saw its capacity increasing, it finishes its coverage job before the one from Travis
* Certbot GitHub repo is configured to require the coverage pipeline to succeed (in whatever that means) to success the overall PR build
So here the suite of events:
1) PR is issued. GitHub expect three pipeline to succeed: AppVeyor CI, Travis CI and Codecov (displayed in the PR page)
2) Codecov receive first the report of AppVeyor coverage. It is 96%. It is a failure for now, because coverage in master (AppVeyor+Travis) is 98.6%.
3) GitHub is reported of the failure on Codecov, so fail the PR build
4) Codecov receive then the report of Travis coverage. It is 98%. It merges it with the report from AppVeyor, leading to the 98.6%. The failure becomes a success.
5) GitHub is reported of the success on Codecov, so, nevermind, the PR build is a success finally!
So we have a CI flow that change its mind. Great. This is because of 2) and 4), and we could expect that Codecov should handle that. This is not the case: it is somewhat misleading, because Codecov adverts a lot about its capability to merge reports, including from different CI. But it is about the final state, not about the transient state, while reports are progressively received.
Two things to things that a transient state is existing, with a result that can change:
* first, from Codecov doc itself, explaining that reports should not be trusted during the CI pipeline execution: https://docs.codecov.io/docs/ci-service-relationship#section-checking-ci-status
* second, is an example of transient state of `cryptography` project, this is advert by Codecov to be a reference of the implementation:
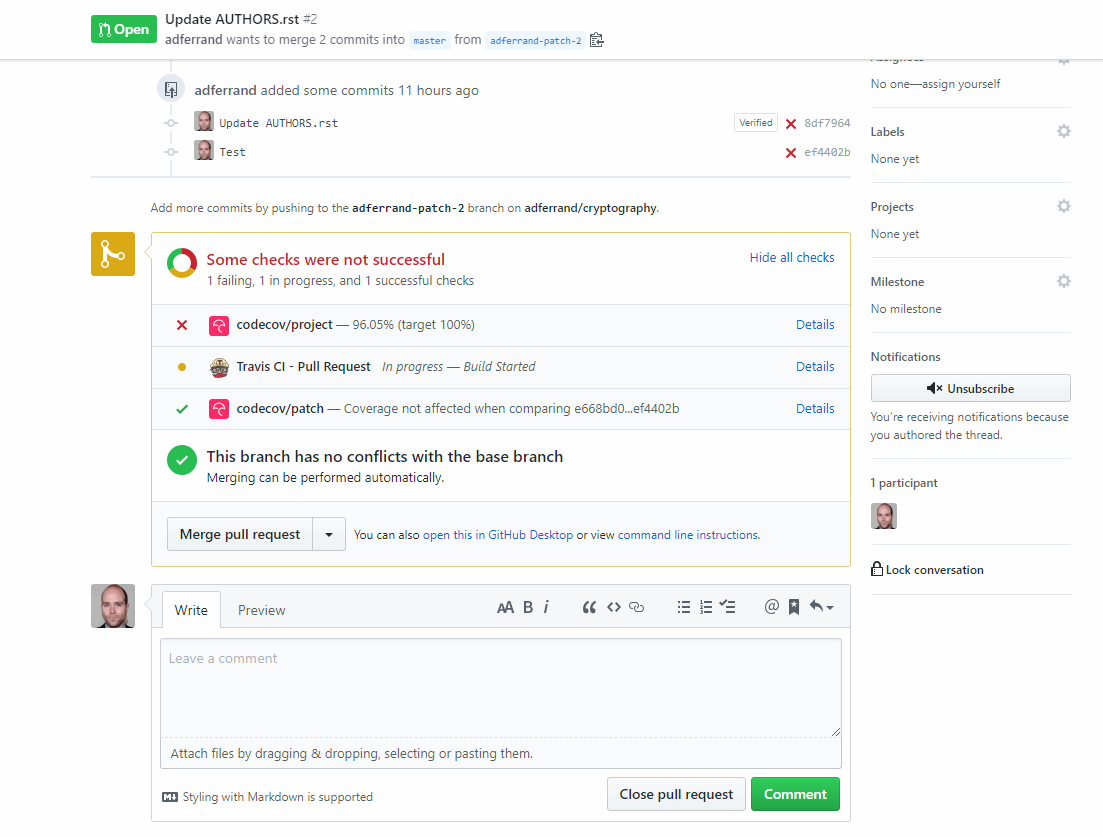
As you can see above, build state of `cryptography` is failing after the first report is received, and until all coverage reports from Travis are received.
So, what can we do about it? Thing is, we are aggregating coverage from very two unrelated sources (two different OS systems), and Codecov has something for that. This is flags: https://docs.codecov.io/docs/flags
Flags allow to flag coverage material depending on any logic you apply to the command that uploaded the coverage report (eg. `codecov -F a_flag`). Then, several logics can be applied on it, for instance having in Codecov UI the capability to filter the coverage other a flag, having status of build for each flag and ... having a report for a specific flag.
So:
1) I modified Travis and AppVeyor to send their report under a specific flag: `linux` or `windows`
2) I created a project specific `.codecov.yml` configuration in Certbot repository, to instruct Codecov to push two separate reports on GitHub build: one for Linux, one for Windows. Each report can be validated against its specific coverage from the `master` branch (more on this just after)
With all of this, now the GitHub is succeeding, because each coverage is validated independently.
I think it is the good approach, because it solves the specific issue here, and because it reflects the logic behind: merging coverage from different OS architectures does not make much sense. It would be a long-term problem, because as I said at the beginning, coverages will slowly decrease as more platform specific code is added in Certbot.
Now, it is not finished. Two things need to be done: an administrator action, and a second PR
Administrator action
Certbot GitHub as a a branch protection rule (Settings > Branches > Branch protection rules). It needs to be changed.
Indeed this rule is expecting the full coverage report (named `codecov/project`) to be valid on a PR. It needs to be changed to expect two coverage reports: `codecov/project/linux` and `codecov/project/windows`. The `codecov/project` needs to be removed.
This can be done once this PR is merged, and the specific coverage reports have been generated on master.
Second PR
Once this PR is merged and administrative actions have been done. I will make a new PR modifying `.codecov.yml` with two things:
* disable the faulty full coverage report, that is not required anymore by GitHub branch protection rules
* modify the `linux` and `windows` reports to validate against the relevant coverage calculated from `master` (indeed, in this PR it is a fixed ratio rule, since the coverage to compare on master is the full coverage one, significantly higher)
* Tag reports
* Set per-project codecov configuration
By removing all the builds on push to master, done in #6804, we also removing the coveralls reports that are necessary to calculate the effect of a PR on code coverage, that is part of the quality gate process.
This PR is reverting #6804, and another implementation preserving the coveralls reports will be done soon.
This reverts commit a468a3b255.
Fixes#6746.
Every commit on master is always the result of a merged PR, that has been tested by Travis. So retesting the merge commit on master is superfluous. This PR uses build conditions to avoid to launch a build for a commit push on master.
I also added the equivalent logic for AppVeyor. Builds cannot received conditions, so it needs to be done on init using Exit-AppVeyorBuild. This command does not fail the build, it finishes it prematurely with success.
* Disable build for commit pushed on master (PR are still tested of course)
* Equivalent exclusion code for AppVeyor
The rerun capability in a test campaign can be a nice feature. It can also a bad design.
It is right that with high level tests, like performance or end-to-end tests, a given test runtime can depend on an external component, outside the scope of the developers, that would spuriously fail. In theses situations, having the capacity to rerun several time a test can be a great benefit. Indeed, as these tests are inherently flaky, the rerun greatly reduces their failure because of external reasons, reducing also the Pierre et le Loup effect (from a well-known french book for children): because tests constantly fail for no reason, you stop to listen to them and to not see when they fail for a real reason.
However this not apply to unit tests, or operations about code quality. For theses executions, the flakiness should not exist: a unit test is supposed to have no external dependency. A rerun approach would just hide a situation that is not desirable for this kind of tests
Also effectively I see that our tests are usually not flaky: so the only effect of the rerun is to give the failure state about a test three times slower. If a test becomes flaky, this should be fixed, and so be visible immediately in our CI.
For these reasons, I remove the travis_retry in the script section of .travis-ci.yml, to call directly tox and let the pipeline fails on the first error.
* Disable rerun feature of Travis
* Update .travis.yml
* Remove completely the retry logic
We always run a full set of CI tests before beginning the release process. The way this would work previously is we would either trigger tests on the `test-everything` branch to run through Travis' web UI or if it was a point release, create a new branch based on `test-everything` but modify `.travis.yml` so the branch that was pulled in to be tested was the point release branch instead of `master`.
This no longer works because the former `test-everything` tests are now only run when Travis automatically runs our tests nightly.
We could create and maintain a separate branch for the purpose of manually running all tests or remove the conditionals from the latest `.travis.yml` file every time before we want to run these tests, but there must be A Better Way™.
This PR makes the change that in addition to running all tests nightly, they would also run on pushes to tested branches other than master. These changes do not affect the tests run on PRs or on commits to `master`.
What is affected is commits to point release branches and branches named `test-*`. (See [.travis.yml](2ddaf3db04/.travis.yml (L177)) for what branches we run tests on.) Running all tests on point release branches automates the step of running our full test suite before doing a point release.
The changes to `test-*` could be a mixed bag, however, since we switched to travis-ci.com over 3 weeks ago, I'm the only one who has used this functionality and I personally prefer things this way. At the very least, since these branches don't seem to be widely used, I think we can make this change and reevaluate if it becomes a problem.
* Test all on push events to non-master branches.
* Move branches section up.
* expand comment
This PR passes the CERTBOT_NO_PIN environment variable to the unit tests tox envs. By setting CERTBOT_NO_PIN to 1 before executing a given tox env, certbot dependencies will be installed at their latest version instead of the usual pinned version.
I also moved the unpin logic one layer below to allow it to be used potentially more widely, and avoid unnecessary merging constraints operation in this case.
As warnings are errors now, latest versions of Python will break now the tests, because collections launch a warning when some classes are imported from collections instead of collections.abc. Certbot code is patched, and warning is ignored for now, because a lot of third party libraries still depend on this behavior.
* Allow to execute a tox target without pinned dependencies
* Correct lint
* Retrigger build.
* Remove debug code
* Added test against unpinned dependencies from test-everything-unpinned-dependencies branch
* Remove duplicated assertion to pass TRAVIS and APPVEYOR in default tox environment.
These tests were running on Ubuntu Precise and Debian Wheezy which have reached their end of life and are no longer maintained by the respective distros. This updates the tests to a newer version of Debian and Ubuntu.
* Remove tests on the deprecated precise.
* Add tests for Xenial.
* update Jessie tests to use Wheezy
* update .travis.yml
Fixes#6659
It appears that the conditional statement if: cron = type works as expected:
on a push event, jobs marked with this statement are completely ignored
on a cron event, these jobs are executed
This PR takes advantages of it, by integrating the specific environments from test-everything branch to be merged into master, and add the conditional statement to execute them only during cron builds.
Once this PR is merged, a cron job can be set to build master at the appropriate time of the day, and test-everything will not be needed anymore.
For execution examples from this branch, see:
during a push event: https://travis-ci.org/adferrand/certbot/builds/480127828
during a cron event: https://travis-ci.org/adferrand/certbot/builds/480130236
* Use the conditional expression in travis.yml to execute jobs from test-everything only during cron executions.
* Update .travis.yml
* Update .travis.yml
* Remove before_install
Fixes#6585.
I wrote up three suggestions for fixing this at https://github.com/certbot/certbot/issues/6585#issuecomment-448054502. I took the middle approach of requiring the user to provide an ACME server to use. I like this better than the other approaches which were:
> Resolve#5938 instead of this issue.
There is value in these tests as is over the compatibility tests in that they don't use Docker and run on different OSes.
> Spin up a local Python server to return the directory object.
Trying to set up a dummy ACME server seemed hacky and error prone.
Other notes about this PR are:
* I put the Pebble setup in `tox.ini` rather than `.travis.yml` as this seems much cleaner and more natural.
* I created a new `tox` environment called `apacheconftest-with-pebble` that reuses the code from `testenv:apacheconftest` so `apacheconftest` can continue to be used with servers other than Pebble like is done in our test farm tests.
* I chose the environment variable `SERVER` for consistency with our integration tests. I chose to not give this environment variable a default but to fail fast when it is not set.
* I ran test farm tests on this PR and they passed.
PR #6568 removed the --quiet option in pip invocations, because this option deletes a lot of extremely useful logs when something goes wrong. However, when everything goes right, or at least when pip install is correctly executed, theses logs add hundreds of lines that are only noise, making hard to debug errors that can be in only one or two lines.
We can have best of both worlds. Travis allows to fold large blocks of logs, that can be expanded directly from the UI if needed. It only requires to print in the console some specific code, that this PR implements in the pip_install.py script when the build is run in Travis (known by the existence of TRAVIS environment variable).
I also take the occasion to clean up a little tox.ini.
Note that AppVeyor does not have this fold capability, but it can be emulated using a proper capture of stdout/stderr delivered only when an error is detected.
* Fold pip install log on travis
* Global test env
* Export env variable
Certbot relies heavily on bash scripts to deploy a development environment and to execute tests. This is fine for Linux systems, including Travis, but problematic for Windows machines.
This PR converts all theses scripts into Python, to make them platform independant.
As a consequence, tox-win.ini is not needed anymore, and tox can be run indifferently on Windows or on Linux using a common tox.ini. AppVeyor is updated accordingly to execute tests for acme, certbot and all dns plugins. Other tests are not executed as they are for Docker, unsupported Apache/Nginx/Postfix plugins (for now) or not relevant for Windows (explicit Linux distribution tests or pylint).
Another PR will be done on certbot website to update how a dev environment can be set up.
* Replace several shell scripts by python equivalent.
* Correction on tox coverage
* Extend usage of new python scripts
* Various corrections
* Replace venv construction bash scripts by python equivalents
* Update tox.ini
* Unicode lines to compare files
* Put modifications on letsencrypt-auto-source instead of generated scripts
* Add executable permissions for Linux.
* Merge tox win tests into main tox
* Skip lock_test on Windows
* Correct appveyor config
* Update appveyor.yml
* Explicit coverage py27 or py37
* Avoid to cover non supported certbot plugins on Windows
* Update tox.ini
* Remove specific warnings during CI
* No cover on a debug code for tests only.
* Update documentation and help script on venv/venv3.py
* Customize help message for Windows
* Quote correctly executable path with potential spaces in it.
* Copy pipstrap from upstream
Main piece of #5810.
* Rename Certbot integration tests
* Remove nginx from certbot tests
* allow for running individual integration tests
* fail under 65
* Add set -e
* Track Nginx coverage and omit it from report later.
* Use INTEGRATION_TEST in script
* add INTEGRATION_TEST=all
* update min certbot percentage
* Remove apacheconftest packages.
The apacheconftests handle installing Apache dependencies, so let's remove it from the general case.
* We don't need to run dpkg -s in before_install.
* Remove augeas sources.
We only needed it for Ubuntu Precise which is dead and it doesn't work in Ubuntu Xenial.
* Upgrade Python 3.6 tests to 3.7.
Let's continue the approach of testing on the oldest and newest versions of Python 3. We will continue testing on Python 3.6 in the nightly tests.
* Revert "We don't need to run dpkg -s in before_install."
This reverts commit e5d35099a7.
* let apacheconftest handle deps
* check_untyped_defs in mypy with clean output for acme
* test entire acme module
* Add typing as a dependency because it's only in the stdlib for 3.5+
* Add str_utils, modified for python2.7 compatibility
* make mypy happy in acme
* typing is needed in prod
* we actually only need typing in acme so far
* add tests and more docs for str_utils
* pragma no cover
* add magic_typing
* s/from typing/from magic_typing/g
* move typing to dev_extras
* correctly set up imports
* remove str_utils
* only type: ignore for OpenSSL.SSL, not crypto
* Since we only run mypy with python3 anyway and we're fine importing it when it's not actually there, there's no actual need for typing to be present as a dependency
* comment magic_typing.py
* disable wildcard-import im magic_typing
* disable pylint errors
* add magic_typing_test
* make magic_typing tests work alongside other tests
* make sure temp_typing is set
* add typing as a dev dependency for python3.4
* run mypy with python3.4 on travis to get a little more testing with different environments
* don't stick typing into sys.modules
* reorder imports
Fixes#5490.
There's a lot of possibilities discussed in #5490, but I'll try and explain what I actually did here as succinctly as I can. Unfortunately, there's a fair bit to explain. My goal was to break lockstep and give us tests to ensure the minimum specified versions are correct without taking the time now to refactor our whole test setup.
To handle specifying each package's minimum acme/certbot version, I added a requirements file to each package. This won't actually be included in the shipped package (because it's not in the MANIFEST).
After creating these files and modifying tools/pip_install.sh to use them, I created a separate tox env for most packages (I kept the DNS plugins together for convenience). The reason this is necessary is because we currently use a single environment for each plugin, but if we used this approach for these tests we'd hit issues due to different installed plugins requiring different versions of acme/certbot. There's a lot more discussion about this in #5490 if you're interested in this piece. I unfortunately wasted a lot of time trying to remove the boilerplate this approach causes in tox.ini, but to do this I think we need negations described at complex factor conditions which hasn't made it into a tox release yet.
The biggest missing piece here is how to make sure the oldest versions that are currently pinned to master get updated. Currently, they'll stay pinned that way without manual intervention and won't be properly testing the oldest version. I think we should solve this during the larger test/repo refactoring after the release because the tests are using the correct values now and I don't see a simple way around the problem.
Once this lands, I'm planning on updating the test-everything tests to do integration tests with the "oldest" versions here.
* break lockstep between packages
* Use per package requirements files
* add local oldest requirements files
* update tox.ini
* work with dev0 versions
* Install requirements in separate step.
* don't error when we don't have requirements
* install latest packages in editable mode
* Update .travis.yml
* Add reminder comments
* move dev to requirements
* request acme[dev]
* Update pip_install documentation
* Use newer boulder config
* Use ACMEv2 endpoint if requested
* Add v2 integration tests
* Work with unset variables
* Add wildcard issuance test
* quote domains
* Drop support for EOL Python 2.6
* Use more helpful assertIn/NotIn instead of assertTrue/False
* Drop support for EOL Python 3.3
* Remove redundant Python 3.3 code
* Restore code for RHEL 6 and virtualenv for Py2.7
* Revert pipstrap.py to upstream
* Merge py26_packages and non_py26_packages into all_packages
* Revert changes to *-auto in root
* Update by calling letsencrypt-auto-source/build.py
* Revert permissions for pipstrap.py
* Add OSX Python2 tests
* Make sure python2 is originating from homebrew on macOS
* Upgrade the already installed python2 instead of trying to reinstall
* Remove extra le-auto tests from master
* Remove dockerfile-dev test from master
* Remove intermediate Python 3.x tests from master
* Reorder travis jobs for speed
These tests are retained in the test-everything branch, which has a Travis cron
job to run nightly.
Removing these speeds up the Certbot Travis builds dramatically for two reasons:
- The Boulder integration tests are slow (10-12 minutes), and it's exceedingly
rare for them to fail on one Python environment but not another.
- The macOS tests take a very long time to run, because they need to wait for
build slots on the limited number of macOS instances, which are often in high
demand.
Occasionally a network error prevents Docker from starting boulder causing
Travis tests to fail like it did at
https://travis-ci.org/certbot/certbot/jobs/282923098. This works around the
problem by using travis_retry to try to start boulder again if it fails.
This also moves the logic of waiting for boulder to start into
tests/boulder-fetch.sh so people running integration tests locally can benefit.
{kind=link}